
Predicting musical instruments by sound
Music has always been a source of inspiration for many. While is it usually considered that an ability to “understand” music is a preference of human beings, the rapidly increasing popularity of streaming services might argue the point. Spotify, Pandora, Apple Music, Amazon Music, just to name a few, are among our favorite apps. But how do they guess what you would like to hear?
To be competitive, the companies have to make better predictions of what you might like, so they use all the information they can get:
-
Your behavior and other’s behaviors, so it can find users with similar tastes and recommending to you what they like (collaborative filtering);
-
Text information available (lyric, press releases, blog posts, social networks);
-
Raw music file itself, coming up with estimates about time signature, key, mode, tempo, and loudness, instruments used.
The third method can be especially helpful with new music, where the streamer doesn’t have elaborate information yet.
I’ll focus here on recognizing musical instruments from raw sound files. For me it’s always been like a game to guess which instruments are performing right now, especially while listening to classical music, so the idea of making computers to recognize them for me inspired me.
The goal is to develop the model which will allow us to recognize music instruments from the sound of it. I used a convolutional neural network, implementing it using Keras - high-level neural networks API, running on top of TensorFlow.
Dataset
To perform the classification of Musical Instruments by sound, we need to find large dataset with records of sound with information about performer. I used The NSynth Dataset from Magenta
Authors intended to create high-quality and large-scale sounds dataset to much those in the image domain (such as MNIST, CIFAR, and ImageNet).
NSynth is an audio dataset containing 305,979 musical notes, each with a unique pitch, timbre, and envelope. For 1,006 instruments from commercial sample libraries, authors generated four seconds, monophonic 16kHz audio snippets, referred to as notes, by ranging over every pitch of a standard MIDI piano (21-108) as well as five different velocities (25, 50, 75, 100, 127). The note was held for the first three seconds and allowed to decay for the final second. This dataset is widely used for music syntheses.
The dataset contains information about instrument family. Frequency counts for instrument classes with Sources as columns a Families as rows:
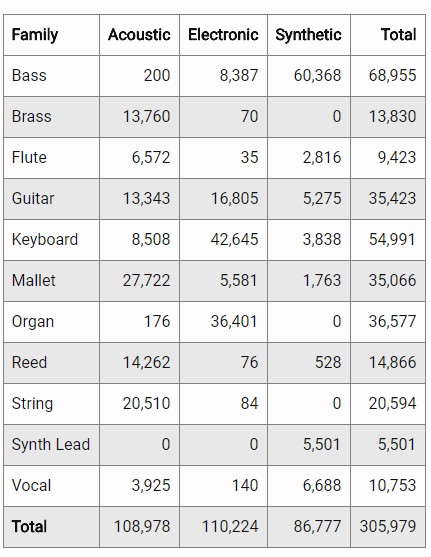
I would like to proceed only with acoustic and electronic, so I ignored synthetic. Also, the dataset contains records of vocal, with is not instrument, so let’s delete them too.
After cleaning, we have 9 classes of instrument families, 1.13 Gb, 9,460 records for training; 371 Mb, 3,039 files for testing.
Building a model
Defining the model:
import keras
from keras import regularizers
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
def build_model():
model = Sequential()
model.add(Conv2D(52, kernel_size=(2, 2), activation='relu', input_shape=(mfcc_output_size, t, channel)))
model.add(Conv2D(64, kernel_size=(2, 2), activation='relu'))
model.add(Conv2D(132, kernel_size=(2, 2), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(64, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(len(labels), activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
return model
model = build_model()
model.summary()

Fitting the model:
model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_val, Y_val))
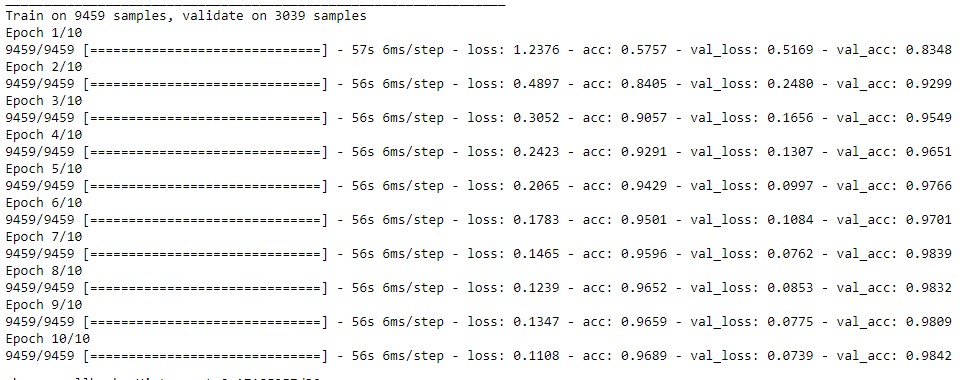
The validation error after 10 epochs is 98.4%. Each epoch took about 1 minute, so the whole training process was completed in 10 minutes (running locally on CPU (AMD FX-8320E Eight-Core Processor 3.5 GHz). There is no need to continue training, as validation error starts to fluctuate after the 7th epoch.
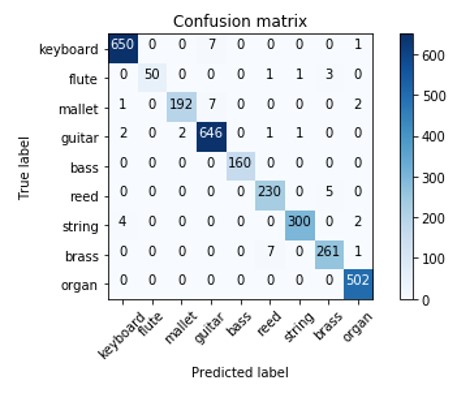
The confusion matrix looks very good! Among miss-predicted values is keyboard predicted as guitar (7 times) and reed predicted as brass (5 times).
Let’s make predictions!
Organ
filename = "organ_electronic_001-048-127.wav"
print("Targeted : " + filename.split('_')[0])
print("Predicted: " + predict(test_path+'/' + filename, model=model))
ipd.Audio(test_path+'/' + filename)
Targeted : organ
Predicted: organ
Guitar
filename = "guitar_acoustic_010-046-025.wav"
print("Targeted : " + filename.split('_')[0])
print("Predicted: " + predict(test_path+'/' + filename, model=model))
ipd.Audio(test_path+'/' + filename)
Targeted : guitar
Predicted: guitar
Piano
filename = "keyboard_acoustic_004-048-075.wav"
print("Targeted : " + filename.split('_')[0])
print("Predicted: " + predict(test_path+'/' + filename, model=model))
ipd.Audio(test_path+'/' + filename)
Targeted : keyboard
Predicted: keyboard
String
filename = "string_acoustic_080-048-025.wav"
print("Targeted : " + filename.split('_')[0])
print("Predicted: " + predict(test_path+'/' + filename, model=model))
ipd.Audio(test_path+'/' + filename)
Targeted : string
Predicted: string
The network guessed all instruments correctly.
Why Convolutional Neural Network works here?
Isn’t it widely known that convolutional neural network works on the images? Why do they work here? Look at the mel power spectrogram (with help of librosa )
audio_path = train_path + '/organ_electronic_104-070-127.wav'
y, sr = librosa.load(audio_path)
S = librosa.feature.melspectrogram(y, sr=sr, n_mels=128)
# Convert to log scale (dB). We'll use the peak power (max) as reference.
log_S = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(12,4))
librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
plt.title('mel power spectrogram, Organ')
plt.colorbar(format='%+02.0f dB')
plt.tight_layout()
ipd.Audio(audio_path)
Organ
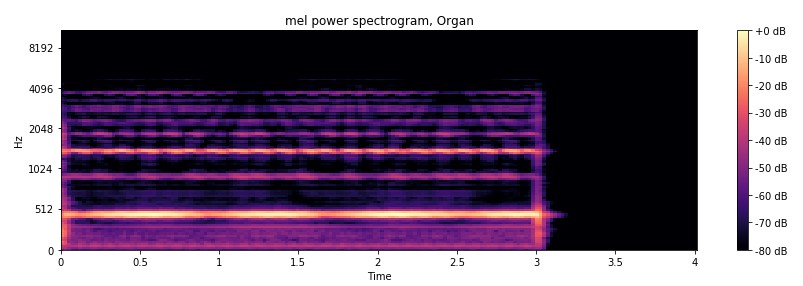
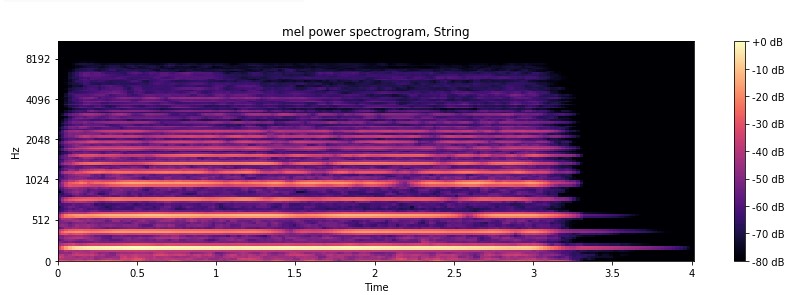
String
Reed
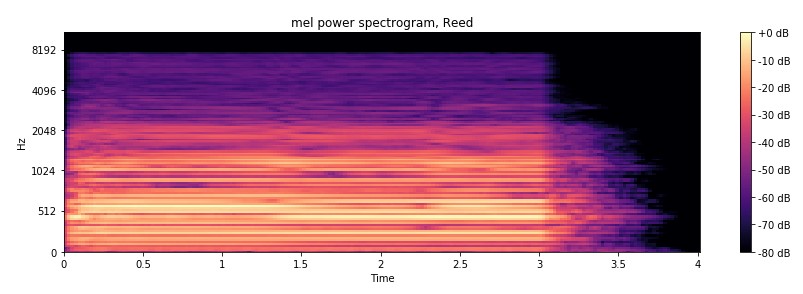
Do you see the distinctive pattern of each instrument? So does CNN.
Future Considerations
I would like to expand the model to learn how to recognize instruments not from the single note, but from actual piece of music with a single predominant instrument. I found suitable dataset – IRMAS. But model, similar to the one I successfully used for NSynth Dataset, when trained on IRMAS dataset (with modification to accommodate more complex data), gives me only 47.5% testing accuracy (number of classes – 9). Although training accuracy was ~97%, no matter how I tried to apply regularization of such model.
Also, it would be interesting to use other sound features, which can be extracted from a sound file using Librosa library, like spectral centroid, roll-off frequency, tonal centroid features, zero-crossing rate, etc. It didn’t make sense to with NSynth (as we already have ~98% test accuracy) but it might help with more complex IRMAS dataset.
References
https://magenta.tensorflow.org/datasets/nsynth
https://github.com/librosa/librosa
http://nbviewer.jupyter.org/github/librosa/librosa/blob/master/examples/LibROSA%20demo.ipynb