What is Graph Database and How to Use It
What is Graph Database?
Unlike traditional relational databases, with a graph database, we have fast access to both data (nodes) and relationships between data points.
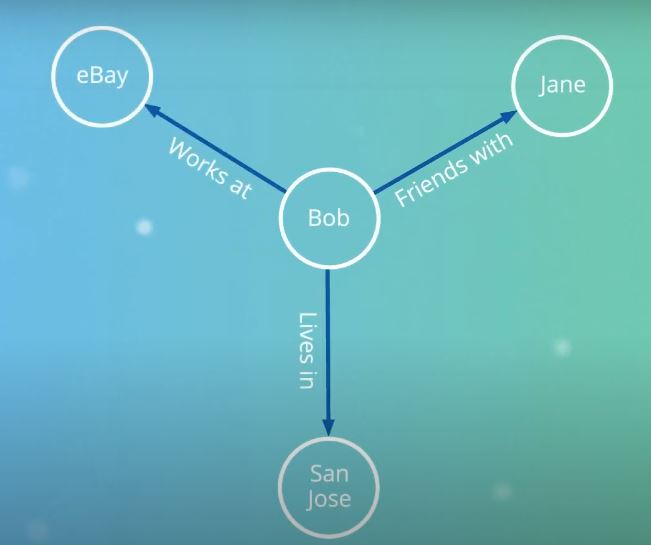
The relation database doesn’t save connection data directly. Relationships can be figured out, of course, but the lookup process is rather costly for relationship intensive queries. And that’s where graph database shines with its connections-first approach to data.

Neo4j is, perhaps, the most popular and easy to use graph platform. Is can be used for a wide variety of tasks, but today we’ll focus on real-time recommendations, creating the system for making movie recommendations.
What’s inside
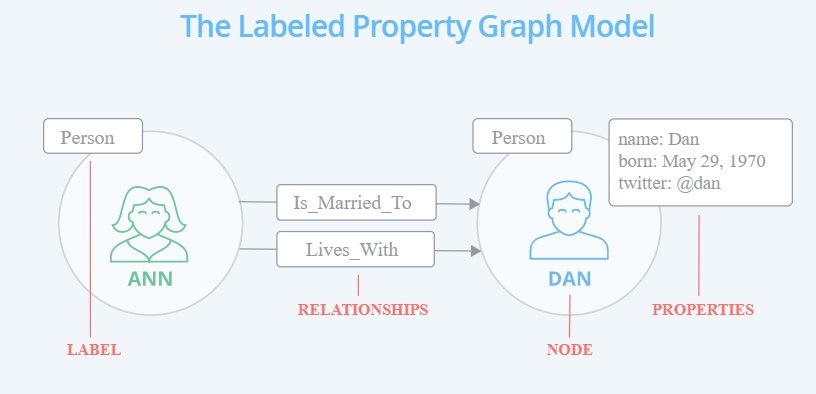
Neo4j database has 4 basic elements:
Nodes
- Nodes are the main data elements
- Nodes are connected to other nodes via relationships
- Nodes can have one or more properties (i.e., attributes stored as key/value pairs)
- Nodes have one or more labels that describe their role in the graph
Relationships
- Relationships connect two nodes
- Relationships are directional
- Nodes can have multiple, even recursive relationships
- Relationships can have one or more properties (i.e., attributes stored as key/value pairs)
Properties
- Properties are named values where the name (or key) is a string
- Properties can be indexed and constrained
- Composite indexes can be created from multiple properties
Labels
- Labels are used to group nodes into sets
- A node may have multiple labels
- Labels are indexed to accelerate finding nodes in the graph
- Native label indexes are optimized for speed
Graph query language Cypher is very easy to learn but very powerful. It allows a user to write moderately complex queries even without prior knowledge of this language.
Real-Time Recommendation Systems
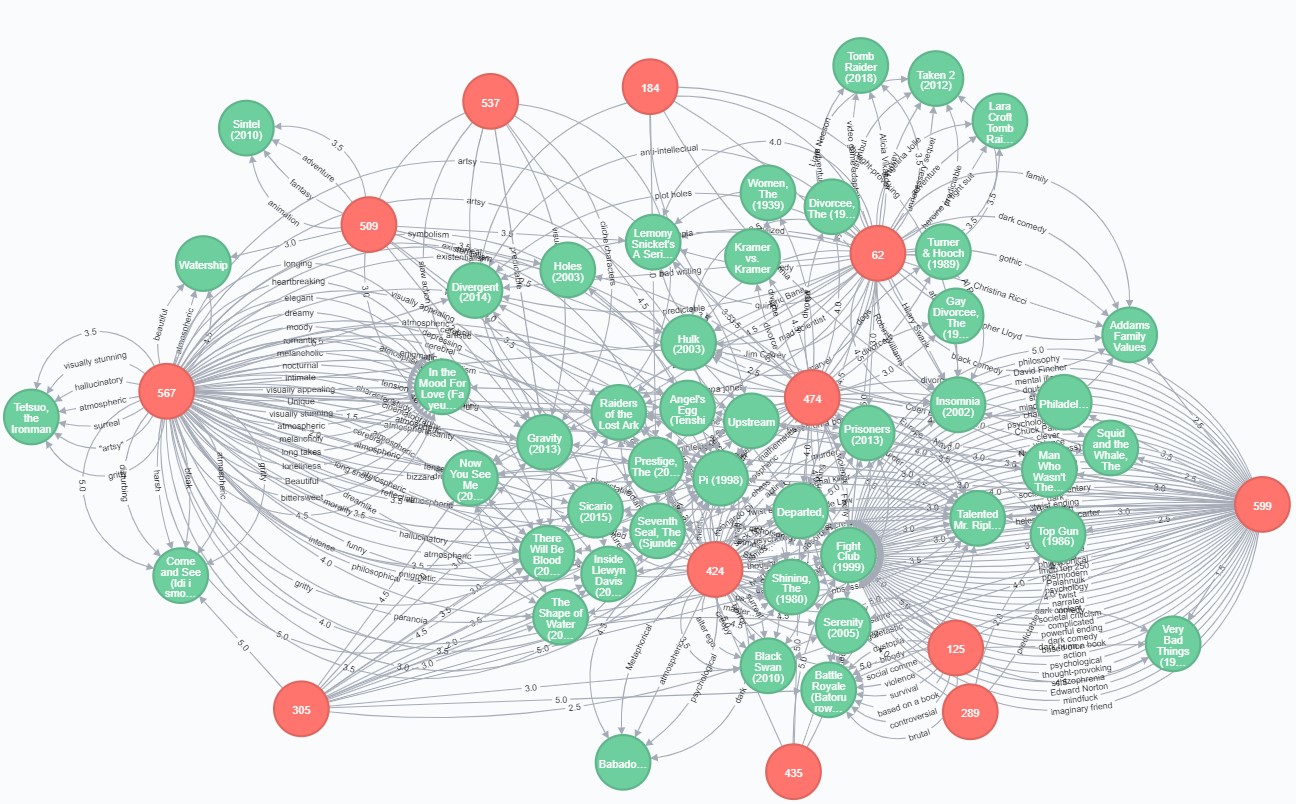
Perhaps, there is no better way to get a feel of the technology than to use it. And one of the applications where graph databases shine is real-time recommendation systems. Connect your customers to products, services, information, or other people based on their user profile, preferences, and past online activity such as product purchases. Real-time recommendation engines play a crucial part in the success of any online business. Another advantage of using a graph database for this model is that it’s easy to visualize and understand the connections and paths with lead us to recommendations.
We’ll start with a movie recommendation system. Fut first we need to get out data.
Dataset Description
We’ll use 2 different datasets:
- MovieLens (Small) dataset, according to its description, describes 5-star rating and free-text tagging activity from http://movielens.org , a movie recommendation service. It contains 100836 ratings and 3683 tag applications across 9742 movies. These data were created by 610 users between March 29, 1996 and September 24, 2018.
- TMDB 5000 Movie Dataset contains 2 csv files: one with detailed information about the movie (budget, genres, original language, and so forth), the second one – contains movie credits – actors, directors, producers. Only csv file with credentials will be used. https://www.kaggle.com/tmdb/tmdb-movie-metadata
Reading from MovieLens
File movies.csv has information about movie id, the title along with the year of release in parentheses, and genres.
Each line of file ratings.csv contains a rating made on a 5-star scale, with half-star increments (0.5 stars - 5.0 stars) of one movie by one user. The user is represented by id only. User ids have been anonymized.
Each row of file tags.csv represents one tag applied to one movie by one user. Tags are user-generated metadata about movies.
All queries have been written using the Cypher language.
To reproduce results, after installation of neo4J engine, go to http://localhost:7474/browser/ and simply enter queries from to the command line at the top of the page:
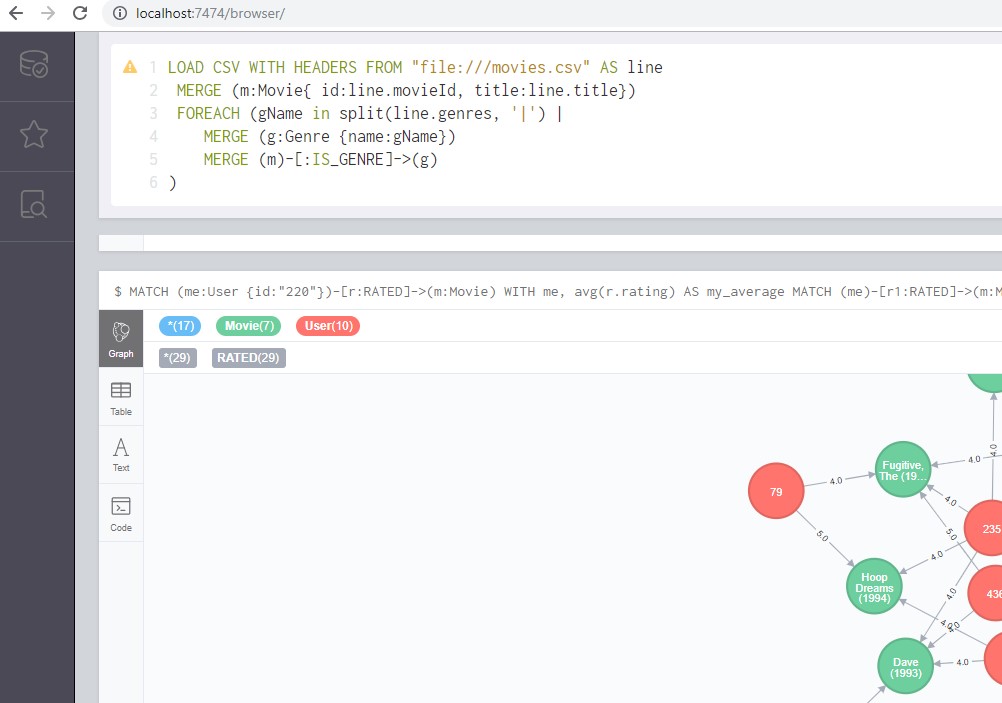
Data from MovieLens dataset can be easily downloaded to neo4j database using LOAD CSV function.
First, I placed csv files to %NEO4J_HOME%/import folder.
Let’s download movie information by creating label Movie with properties id and title and label Genre with the single property title:
LOAD CSV WITH HEADERS FROM "file:///movies.csv" AS line
MERGE (m:Movie{ id:line.movieId, title:line.title})
FOREACH (gName in split(line.genres, '|') |
MERGE (g:Genre {name:gName})
MERGE (m)-[:IS_GENRE]->(g)
)
Added 9762 labels, created 9762 nodes, set 19504 properties, created 22084 relationships, completed after 38484 ms.
By downloading data from ratings.csv we will create label User with only property id (because data about users are anonymized) and connection RATED with property rating: (User)-[:RATED { rating:}]->(Movie).
LOAD CSV WITH HEADERS FROM "file:///ratings.csv" AS line
MATCH (m:Movie {id:line.movieId})
MERGE (u:User {id:line.userId})
MERGE (u)-[:RATED { rating: toFloat(line.rating)}]->(m);
Added 610 labels, created 610 nodes, set 101446 properties, created 100836 relationships, completed after 695343 ms.
Tags:
LOAD CSV WITH HEADERS FROM "file:///tags.csv" AS line
MATCH (m:Movie {id:line.movieId})
MATCH (u:User {id:line.userId})
CREATE (u)-[:TAGGED { tag: line.tag}]->(m);
Set 3683 properties, created 3683 relationships, completed after 21062 ms.
File Links.csv contains 3 different ids of each movie: movieId – the one used in MovieLens dataset, imdbId – is corresponding to IMDB dataset and tmdbId – id corresponding to tmdb https://www.themoviedb.org/ dataset, which we’ll use to get information about actors and directors of the movies. Let’s add to each movie new property – tmdbId:
LOAD CSV WITH HEADERS FROM "file:///links.csv" AS line
MATCH (m:Movie {id:line.movieId})
SET m.tmdbId=line.tmdbId;
Set 9734 properties, completed after 63423 ms.
Reading from TMDB 5000 Movie Dataset
Now let’s proceed with information about actors and directors. As the content of tmdb_5000_credits.csv is not that easy to download to neo4j (csv with JSON format for some columns content) and, taking into the consideration that we don’t need all the information from this file (we will not use, for example, information about Director of Photography of Casting Director to make a recommendation, with all the respect to them), I created create simple Python application wich read all the info from tmdb_5000_credits.csv file, filter it, and created csv file with easy to read for neo4j data. The following csv files were obtained:
The content of file roles.csv:
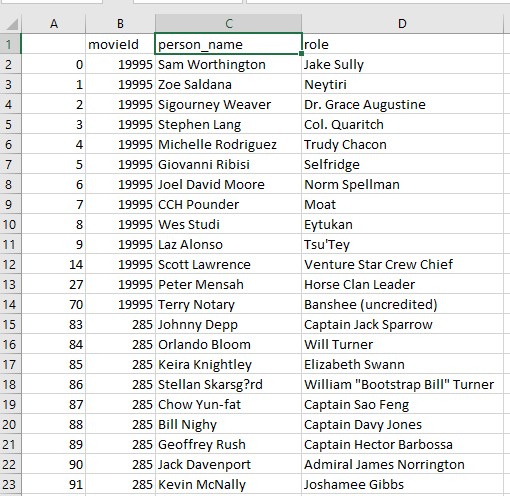
And directors.csv:
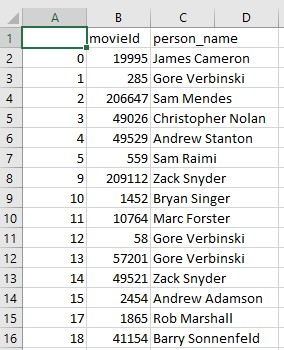
Now we can go back to neo4j and read data about directors and actors:
LOAD CSV WITH HEADERS FROM "file:///directors.csv" AS line
MATCH (m:Movie{ tmdbId:line.movieId})
MERGE (p:Person{name:line.person_name})
MERGE (p)-[:DIRECTED]->(m);
Added 339 labels, created 339 nodes, set 339 properties, created 1889 relationships, completed after 13784 ms.
LOAD CSV WITH HEADERS FROM "file:///roles.csv" AS line
MATCH (m:Movie{ tmdbId:line.movieId})
MERGE (p:Person{name:line.person_name})
CREATE (p)-[r:ACTED_IN] ->(m)
SET r.role= line.role;
Added 2922 labels, created 2922 nodes, set 31782 properties, created 28926 relationships, completed after 279049 ms.
Here is general information about the obtained database:
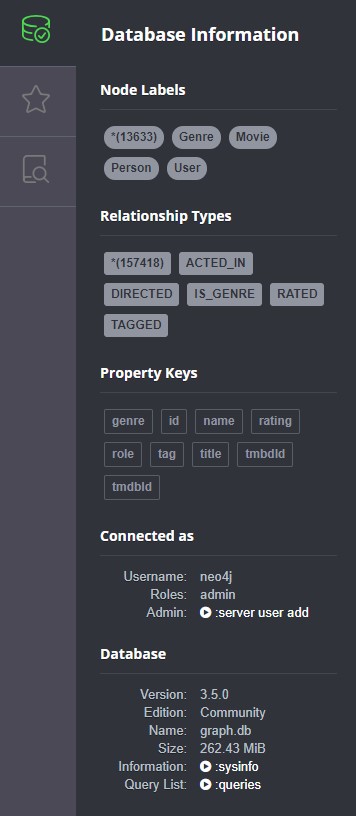
Now we have all the data we need in our database, we can proceed to create a recommendation engine. You can find a content-based approach in this post, and a collaborative filtering model here.