
Movie Recommendation System Using Graph Database - Collaborative Filtering
Today we’ll take the final step to create a model for the movie recommendation system. We all like the way services as Netflix shows us just the movie we’ll want to watch today, don’t we? The perfect way to do it is to use a content-based or collaborative filtering model.
In previous posts, we In previous posts, we get to known what is to neo4j database and how to read data there, and created a content-based filtering model. Today we’ll build a collaborative filtering recommendation engine.
Neo4j fits perfectly for this task. We’ll have to use connections between entities, like find movies likes by user1 which also are liked by other users, and then find movies that other users liked, but user1 hasn’t seen. Using traditional relational databases will lead to a large number of joints, which are very expensive for RDBMS. With a graph database, on the other hand, we have fast access to both data (user, movie, genre) and relationships between them. As all relationships are easily and quickly acceptable, it allows us to process queries very fast, enabling using the model for real-time recommendation engines.
First, let’s examine how our data looks like. To do that, let’s run the following Cypher query to retweet all genres, actors, and director of a movie:
MATCH (m:Movie {title: "Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)"})-[:ACTED_IN|:IS_GENRE|:DIRECTED]-(p)
RETURN m, p
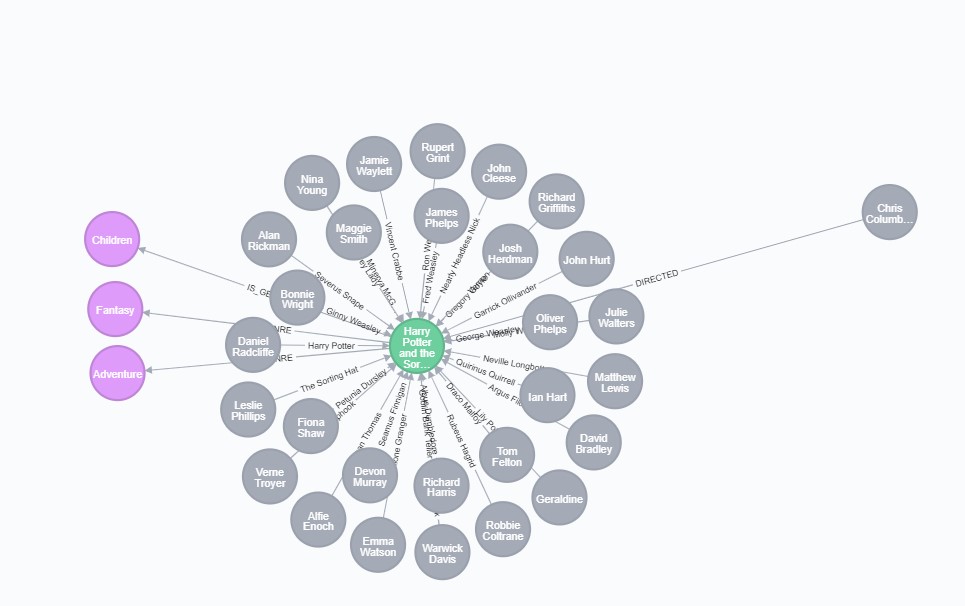
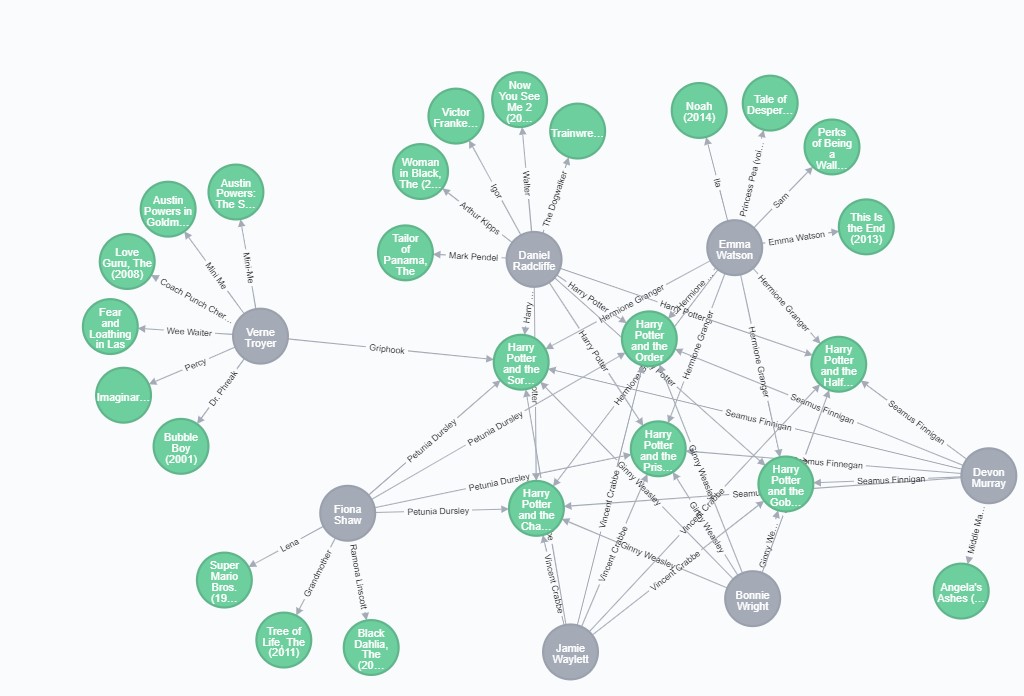
Movies with shared actors or directors (connected thought 2nd-degree connection):
MATCH q=(m:Movie {title: "Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)"})-[:ACTED_IN |:DIRECTED*..2]-(p)
RETURN q LIMIT 50
Now, when we are familiar with data, let’s build find some recommendations, starting with the simplest one and gradually increasing the complexity of our queries.
Collaborative Filtering
The approach when we are taking into consideration only what other users liked is called Collaborative Filtering.
Let’s find movies targeted user likes, then find users who also liked that movies, and recommend movies that other users liked but which our user haven’t seen (rated), sorted by the number of paths that led to a particular recommendation.
MATCH (me:User{id:'220'})-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other:User)-[r3:RATED]->(m2:Movie)
WHERE r1.rating > 3 AND r2.rating > 3 AND r3.rating > 3 AND NOT (me)-[:RATED]->(m2)
RETURN distinct m2 AS recommended_movie, count(*) AS score
ORDER BY score DESC
LIMIT 9

As each user tends to give higher or lower ratings in general, let’s filter by the average rating of a particular user, rather than just constant “3”:
MATCH (me:User{id:'220'})-[r:RATED]-(m)
WITH me, avg(r.rating) AS average
MATCH (me)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other:User)-[r3:RATED]->(m2:Movie)
WHERE r1.rating > average AND r2.rating > average AND r3.rating > average AND NOT (me)-[:RATED]->(m2)
RETURN distinct m2 AS recommended_movie, count(*) AS score
ORDER BY score DESC
LIMIT 9

Here is a visualization of some connections in the previous query:
MATCH (me:User{id:'220'})-[r:RATED]-(m)
WITH me, avg(r.rating) AS average
MATCH (me)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other:User)-[r3:RATED]->(m2:Movie)
WHERE r1.rating > average AND r2.rating > average AND r3.rating > average AND NOT (me)-[:RATED]->(m2)
RETURN distinct m2, other, me, m AS recommended_movie, count(m2) AS score
ORDER BY score DESC
LIMIT 20
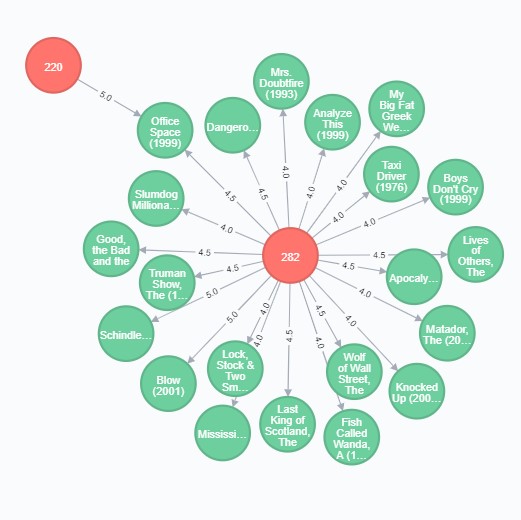
“Similar” Users
Instead of taking into consideration the opinion of all users in the system, let’s find most “similar” users; users who have the same taste. The easiest way to do so is to find the correlation coefficient between the targeted user and others, and then use ratings given only by “same-minded” users.
We’ll use the sample Pearson correlation coefficient, which is defined as follows:

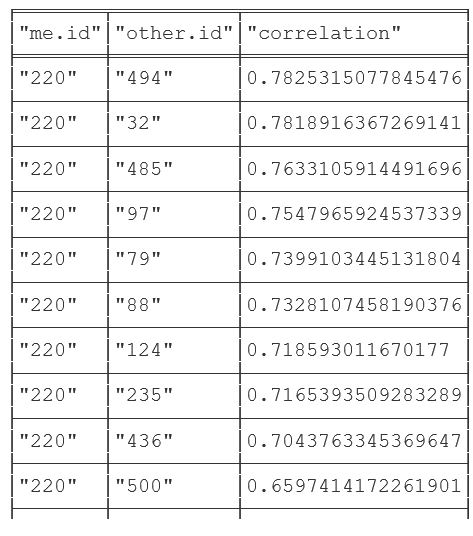
Let’s find users with a large correlation coefficient between ratings given by our user and all others:
MATCH (me:User {id:"220"})-[r:RATED]->(m:Movie)
WITH me, avg(r.rating) AS my_average
MATCH (me)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other)
WITH me, my_average, other, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (other)-[r:RATED]->(m:Movie)
WITH me, my_average, other, avg(r.rating) AS other_average, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating- my_average) * (r.r2.rating- other_average) ) AS a,
sqrt( sum( (r.r1.rating - my_average)^2) * sum( (r.r2.rating - other_average) ^2)) AS b,
me, other
WHERE b <> 0
RETURN me.id, other.id, a/b as correlation
ORDER BY correlation DESC LIMIT 10
Let’s show how does similarly rated movies look like for targeted user and the one with the largest correlation value:
MATCH (me:User {id:"220"})-[:RATED]->(m:Movie)
MATCH (other:User {id:"494"})-[:RATED]->(m:Movie)
RETURN me, other, m
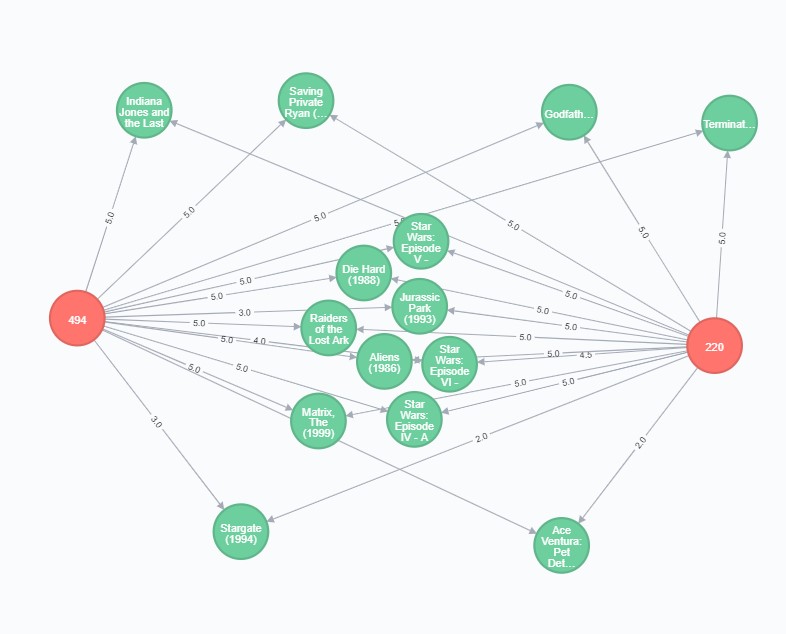
As we see, highly rated movies by user 220 are also highly rated by user 494; poorly rated movies by user 220 are also poorly rated by user 494.
Positive Correlated Recommendations
Let’s use this property to find recommended movies:
MATCH (me:User {id:"220"})-[r:RATED]->(m:Movie)
WITH me, avg(r.rating) AS my_average
MATCH (me)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other)
WITH me, my_average, other, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (other)-[r:RATED]->(m:Movie)
WITH me, my_average, other, avg(r.rating) AS other_average, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating- my_average) * (r.r2.rating- other_average) ) AS a,
sqrt( sum( (r.r1.rating - my_average)^2) * sum( (r.r2.rating - other_average) ^2)) AS b,
me, other
WHERE b <> 0
WITH me, other, a/b as correlation
ORDER BY correlation DESC LIMIT 10
MATCH (other)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (me)-[:RATED]->(m) )
WITH m, SUM( correlation* r.rating) AS score, COLLECT(other) AS other
RETURN m, other, score
ORDER BY score DESC LIMIT 10

Here we see the movie title, list of users, opinion of those were taking into consideration, and score, which sum by the number of users of the rating given by user multiplied by the correlation coefficient of this user.
Here is the visualization.
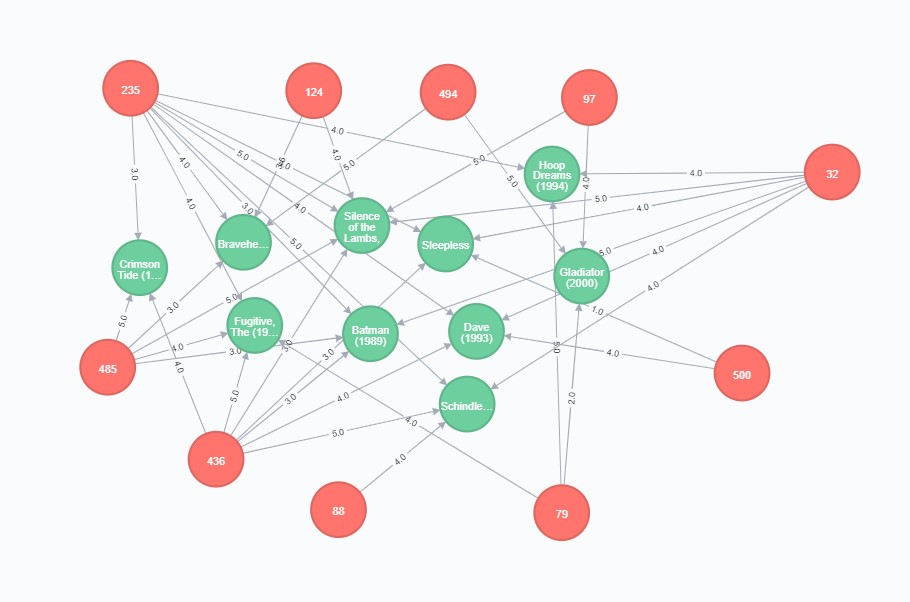
We can find here user who are highly correlated with user 220, and their ratings toward chosen movies. Six of such users gave a high rate to the leading movie Silence of the Lambs.
Negatively Correlated Recommendations
Similarly, we can find users with negative correlation: if the targeted user likes particular movies, the user with high negative correlation will hate it, and the opposite. Then we can use such “anti-recommendation” and hide these movies from the user in order not to upset him.
MATCH (me:User {id:"220"})-[r:RATED]->(m:Movie)
WITH me, avg(r.rating) AS my_average
MATCH (me)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(other)
WITH me, my_average, other, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (other)-[r:RATED]->(m:Movie)
WITH me, my_average, other, avg(r.rating) AS other_average, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating- my_average) * (r.r2.rating- other_average) ) AS a,
sqrt( sum( (r.r1.rating - my_average)^2) * sum( (r.r2.rating - other_average) ^2)) AS b,
me, other
WHERE b <> 0
WITH me, other, a/b as correlation
ORDER BY correlation ASC LIMIT 10
MATCH (other)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (me)-[:RATED]->(m) )
WITH m, SUM( correlation* r.rating) AS score, COLLECT(other) AS other
RETURN m, other, score
ORDER BY score ASC LIMIT 10

References
http://guides.neo4j.com/sandbox/recommendations
https://neo4j.com/developer/movie-database/#_import_instructions
https://github.com/citruz/movies4j
https://neo4j.com/blog/real-time-recommendation-engine-data-science/
https://en.wikipedia.org/wiki/Jaccard_index
https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
https://www.kaggle.com/tmdb/tmdb-movie-metadata
https://grouplens.org/datasets/movielens/
https://doi.org/10.1145/2827872