
Movie Recommendation System Using Graph Database - Content-Based Filtering
In the previous post, we what is to neo4j database and read data there. Today, we’ll dive deeper into the content-based approach to build a movie recommendation system.
First, let’s examine how our data looks like. To do that, let’s run the following Cypher query to retweet users who rated or tagged this movie:
MATCH (m:Movie {title: "Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001)"})-[:RATED|:TAGGED]-(u)
RETURN m, u LIMIT 25
Now, when we are familiar with data, let’s build find some recommendations, starting with the simplest one and gradually increasing the complexity of our queries.
Content-Based Filtering
Let’s use tags: find tags our user gave o describe movies he likes, and find other movies with the same tags (not taking into consideration whether other users, who described other movies like that movies or not). Here are the movies and tags of movies of our user’s liking:
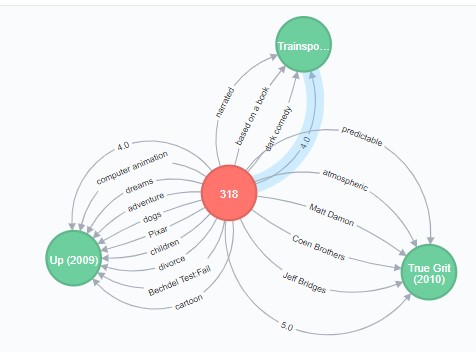
MATCH (me:User{id:'318'})-[r:RATED]-(m)
WITH me, avg(r.rating) AS average
MATCH (me)-[t1:TAGGED]->(m:Movie)-[r:RATED]-(me)
MATCH (other:User)-[t2:TAGGED]->(m1:Movie)
WHERE r.rating > average AND t1.tag=t2.tag AND NOT (me)-[:TAGGED]->(m1) AND NOT (me)-[:RATED]->(m1)
RETURN m1, other
Every movie in this subgraph contains a tag our user liked.
Now let’s use a collaborative approach together with information about the content of the movie (we have actors, directors, and genre).
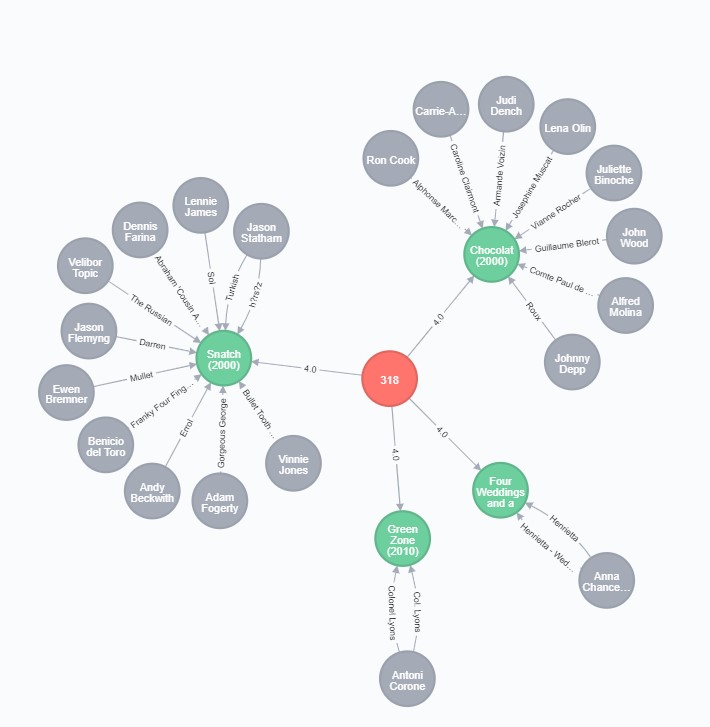
First, let’s found actors on movies which our user liked sorted by the number of time a particular actor appears in such movies:
MATCH (me:User{id:'318'})-[r:RATED]-(m:Movie)
WITH me, avg(r.rating) AS average
MATCH (me)-[r:RATED]->(m:Movie)-[:ACTED_IN]-(p:Person)
WHERE r.rating > average
RETURN p as actor, COUNT(*) AS score
ORDER BY score DESC LIMIT 10
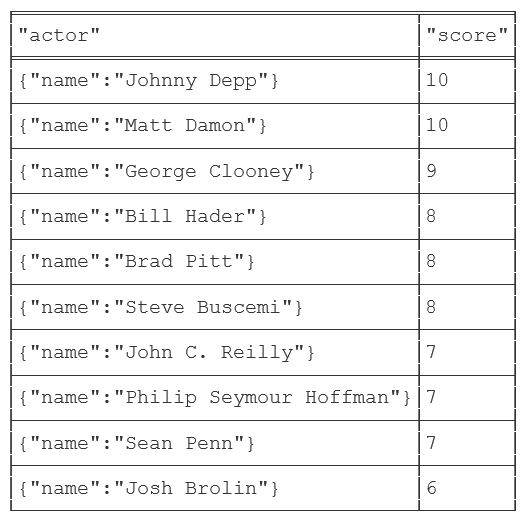
Apparently, our user #318 likes Johnny Depp. Here is an illustration:
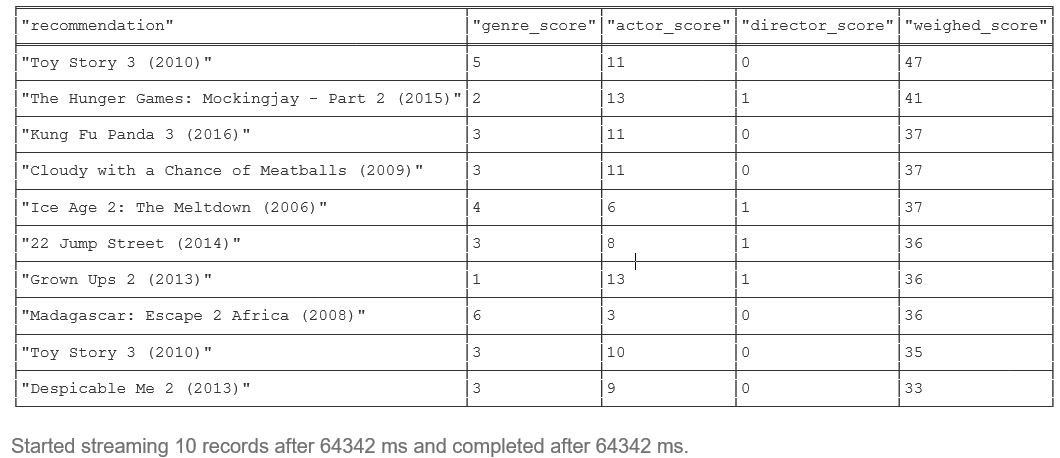
Now let’s use combined information about favorite actors, directors, and genres to provide the user with weighted recommendation sorted by the number of overlapping paths that lead to a particular recommended movie:
MATCH (me:User{id:'318'})-[r:RATED]-(m:Movie)
WITH me, avg(r.rating) AS average
MATCH (me)-[r:RATED]->(m:Movie)
WHERE r.rating > average
MATCH (m)-[:IS_GENRE]->(g:Genre)<-[:IS_GENRE]-(rm:Movie)
WITH me, m, rm, COUNT(*) AS gs
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Person)-[:ACTED_IN]->(rm)
WITH me, m, rm, gs, COUNT(a) AS as
OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Person)-[:DIRECTED]->(rm)
WITH me, m, rm, gs, as, COUNT(d) AS ds
MATCH (rm)
WHERE NOT (me)-[:RATED]->(rm)
RETURN rm.title AS recommendation,
gs as genre_score, as as actor_score, ds as director_score,
(5*gs)+(2*as)+(5*ds) AS weighed_score
ORDER BY weighed_score DESC LIMIT 10
5, 2, 5 are parameters we can adjust if we want to give more weight to either of the categories.
Here is a somewhat simplified query with only actors to visualize connection:
MATCH (me:User{id:'318'})-[r:RATED]-(m:Movie)
WITH me, avg(r.rating) AS average
MATCH (me)-[r:RATED]->(m:Movie)
WHERE r.rating > 4.5
MATCH (m)<-[:ACTED_IN]-(a:Person)-[:ACTED_IN]->(rm)
MATCH (rm)
WHERE NOT (me)-[:RATED]->(rm)
RETURN rm, a, me ,m LIMIT 50
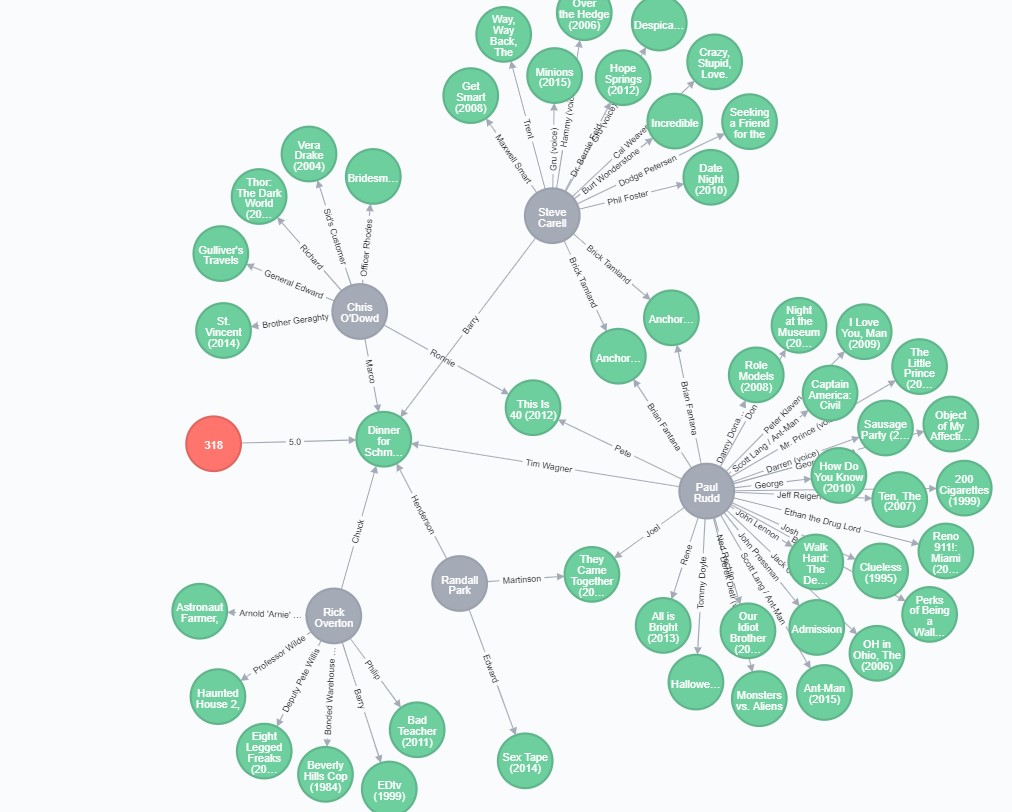
It shows that our user liked movie Dinner for Schmucks (2010), where Paul Rudd, Rick Overton, and others played, so we’ll take a look at the movies they played at. In the original query, we sorted recommendations by the number of overlapping paths that lead to a particular recommended movie.
Using the Jaccard index as a similarity metric
By now, we used the number of paths that lead to particular movies as a score. Now let’s use the Jaccard index as a similarity metric. It is calculated as cardinality (number of elements) of the intersection of 2 sets divided by the cardinality of the union of 2 sets:
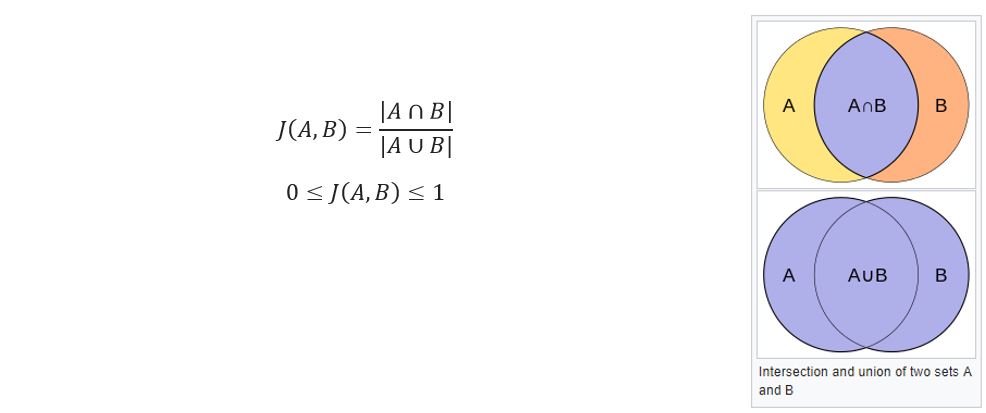
Let’s show how does it work:
MATCH (me:User{id:'220'})-[r:RATED]-(m:Movie)
WITH me, avg(r.rating) AS mean
MATCH (me)-[r:RATED]->(m:Movie)
WHERE r.rating =5
MATCH (m)-[:ACTED_IN|:DIRECTED]-(t)-[:ACTED_IN|:DIRECTED]-(other:Movie)
WHERE NOT (me)-[:RATED]->(other)
WITH me, m, other, COUNT(t) AS intersection, COLLECT(t.name) AS i
MATCH (m)-[:ACTED_IN|:DIRECTED]-(mt)
WITH me, m,other, intersection,i, COLLECT(mt.name) AS s1
MATCH (other)-[:ACTED_IN|:DIRECTED]-(ot)
WITH me, m,other,intersection,i, s1, COLLECT(ot.name) AS s2
WITH me, m,other,intersection,s1,s2
WITH me, m,other,intersection,s1+filter(x IN s2 WHERE NOT x IN s1) AS union, s1, s2
RETURN m.title, other.title, s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 20
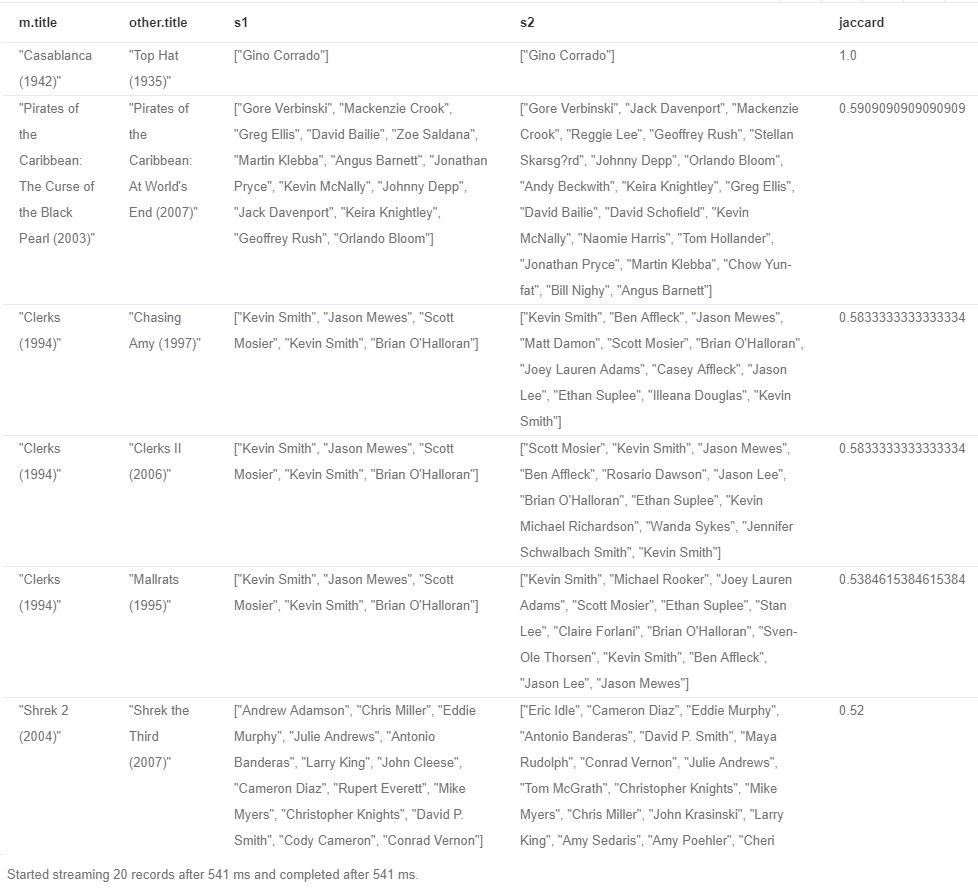
Except for obvious recommendations like movies from the same sequence, we got pretty good math of “Clerk” and “Chasing Amy” and so forth.
Most queries used in this post took about 200-500 ms to process. The longest query took ~60000 ms, in RDBMS it would require ~10 joints and would take much longer.
Another advantage of using a graph database for this model is that it’s easy to visualize the connections and paths that led us to a particular result, and by doing so, to understand the underlying patter better.
In next post, we’ll create colaborative filtering model.